「主權AI」成全球新戰略,台灣如何跟上腳步?【獨立特派員】
加入公視會員,
按讚收藏你關注的報導
AI大腦缺台味 繁中語料陷邊緣
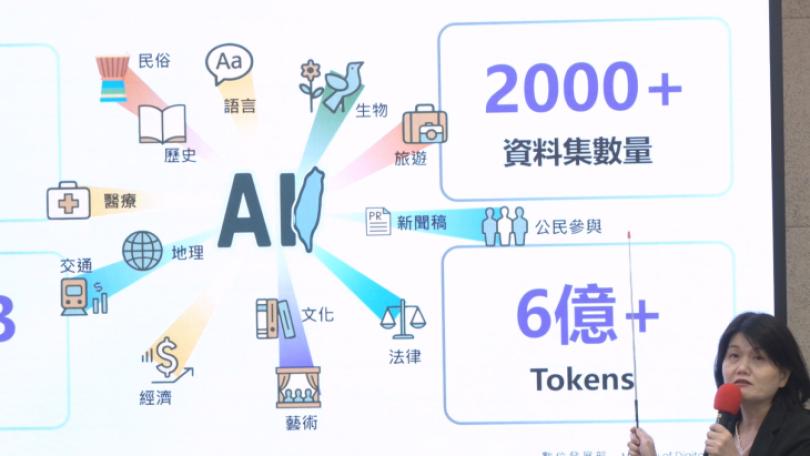
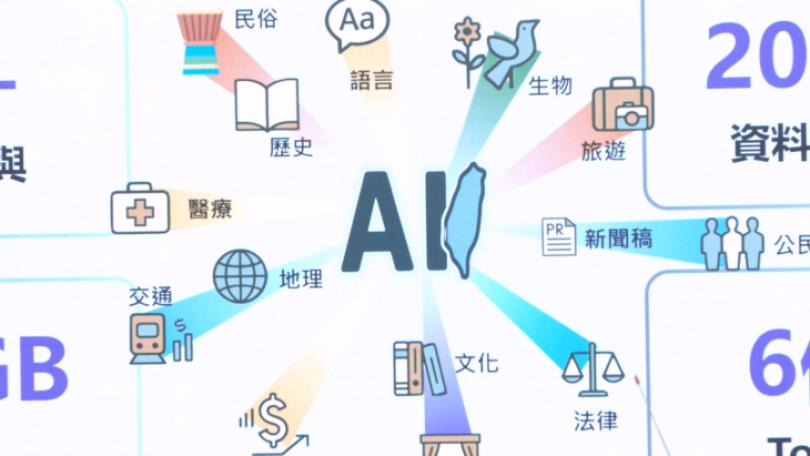
生成式AI已深入生活。然而,其大型語言模型(LLM)訓練仰賴大量語料。數據顯示,訓練語料近五成為英文,而中文語料雖佔5%,卻以簡體中文內容為大宗。
資訊經理人協會理事長蔡祈岩觀察,國際AI模型問答時常出現簡體字或中國大陸用語。數位發展部次長葉寧憂慮,大量中國大陸中文資料被汲取後,可能導致LLM無法反映台灣觀點,使台灣視角在AI世界中被邊緣化。因此,台灣必須主動補足缺口,為AI注入台灣在地化的知識、價值與用語。

國產TAIDE模型 出擊數位主權
為應對「數位主權」挑戰,台灣於2023年4月組建國家隊,發展「主權AI」。國家高速網路與計算中心主任張朝亮指出,主權AI關鍵要素是資料、算力及AI模型。國家隊目標是打造可信賴且了解台灣的LLM TAIDE。
中研院資訊科學研究所副研究員黃瀚萱說明,TAIDE團隊以開源國際預訓練模型為基底,運用大量台灣在地語料訓練,將國際模型轉化為台灣在地化模型。TAIDE已陸續釋出七顆開源模型。最新模型含460億token的繁體中文訓練資料,容量240G,資料源自公部門與新聞等授權資料。
TAIDE以「可信任」為目標,透過持續預訓練與微調。團隊進一步發展G-TAIDE,應用於政府公文系統,確保處理具隱私或機密公文時,模型能在本地端使用,排除隱私外流疑慮。
小主機跑得動 紮根教育應用
TAIDE模型展現本土應用優勢。臺南大學資工系教授李健興選擇TAIDE,開發專才專用的AI機器人作為國小雙語老師。他指出,TAIDE模型能更好地理解台灣本土文化及繁體中文(正體中文),效果優於現有主流LLM。
李健興表示,TAIDE的12b模型僅需單一主機即可運行。這意味著未來中小學即使網路不穩,也能使用AI老師,不需依賴國外大型語言模型主機。更重要的是,師生互動資料能留在台灣。他認為,TAIDE模型已足夠用於本土語言教學,且學習數據的回饋更能助益TAIDE成長,達成雙贏。

資源人力有限 難追國際速度
儘管TAIDE本土化應用具優勢,台灣AI發展仍面臨追趕國際大廠速度的挑戰。大型語言模型專家林彥廷比喻,本土開發的模型如同高中生,而國際巨頭已是大學生或研究生水平。
台灣在經費投入上與國際大廠有巨大落差。黃瀚萱指出,TAIDE計畫一整年預算,含GPU採購,甚至不及國際模型DeepSeek單次訓練成本。林彥廷表示,台灣訓練資料量、軟體基礎建設皆不如國外大廠,國外已形成高效的工廠式流水線作業,能不斷加速發布新模型,主權AI開發則缺乏此體系。
發展基礎建設 提升AI競爭力
林彥廷認為,台灣應著重打造AI基礎建設,而非僅追求單一模型。他建議TAIDE計畫應將硬體與資料開放給學界與產業界共享使用,以奠定基礎。他強調,台灣雖能打造最先進AI晶片,卻難為AI大腦注入台灣的靈魂。
葉寧表示,數發部將從算力、資料、資金、人才等面向,透過相關方案提升AI基本環境,發展主權AI。然而,台灣超級電腦全球排名第14,算力遠不及鄰近國家。張朝亮指出,大的算力需巨額投資。國科會計畫持續建置,目標提供約15個百萬瓦以上的AI算力供台灣開發使用。
資料著作權衝突 法規建置保守
AI的「石油」資料,是台灣發展AI的另一難題。法律科技公司創辦人兼律師陳啟桐指出,AI訓練資料受著作權保護,造成著作權人與資料利用者間的法律衝突。他處理的中央社著作權糾紛,凸顯開發者即使取用開源資料集,仍可能面臨法律風險。
數發部為此提出「促進資料創新利用發展條例」草案,希望由公部門帶頭共享資料。葉寧強調,從開放到共享資料是重要一步,須有法源依據,以平衡科技進步與人民權益保障。
陳啟桐表示,台灣立法方向相對保守,草案將兼顧著作權人取得授權金的需求,可能採標準授權條款與授權金。

產學界攜手 共建本土特色語料
在法規建置的同時,產學界也主導了另一條發展路徑。陳啟桐提到,延續Taiwan-LLM的「Project TAME」(繁中專家模型),利用台灣的判決、法規等資料訓練,使其在台灣法律評測集表現優於其他LLM。
此外,資訊經理人協會發起「Taiwan Tongues」(台灣通用語料庫)計畫,號召各界貢獻台語、客語等台灣語料。Taiwan Tongues執委會主委胡長松指出,文學作品有助於保留台灣的說話腔調。蔡祈岩表示,該計畫目標邁向10億級語料,並與全球AI模型洽談,未來將從此語料庫取得台灣授權語料。
林彥廷總結,主權AI是培養人才的必要名義。透過AI解決本土問題、持續培養人才,台灣才能在未來浪潮中維持競爭力。台灣主權AI挑戰剛起步,如何合法取得語料,縮小法律與實務落差,是關鍵所在。