數發部首度釋出主權AI語料庫 貼近台灣文化與語言
加入公視會員,
按讚收藏你關注的報導
發布時間:
更新時間:
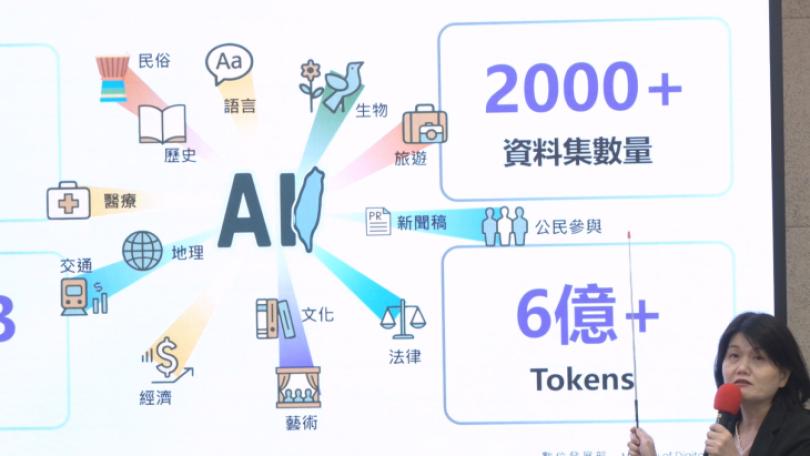
AI浪潮下台灣面臨主權AI挑戰,因為華文語料多以簡體為主,為了讓AI模型的訓練更貼近台灣的語言和文化,數位發展部今(24)日首度發布台灣主權AI訓練語料庫,目前已有超過200個政府機關投入,上架2000多筆的資料集,希望透過主動釋出的作法,方便AI模型訓練學習,建立台灣文化在AI時代的話語權。
進入數位發展部剛發布的台灣主權AI訓練語料庫,申請後取得使用資格,如果搜尋「土豆」一詞,會發現教育部的辭典,呈現「土豆」在台灣是指「花生」,可是在中國卻代表的是「馬鈴薯」,差別很大。
不過,國際的AI模型訓練上,因為華文語料多以簡體為主,AI學習後會把「土豆」就解釋成「馬鈴薯」,為了避免這種情況的不斷發生,數位發展部24日發布台灣主權AI訓練語料庫,強調目前已有超過200個政府機關投入,上架2000多筆的資料集。
數發部資料創新司長莊明芬表示,「這些資料涵蓋了我們文化藝術語言、教育醫療地理交通等等,都是一些高品質的一個資料。」
像是文化部的國家文化記憶庫,提供台灣的族群文化、宗教民俗等資料,具有台灣獨特的文化風貌。教育部提供的語言辭典,涵蓋台語、客語等,強化AI模型,對台灣用詞的精準度。
文化部綜合規劃司魏秋宜說道,「主動積極的盤點跟提供資料,協助主權AI進行訓練,提升主權AI在台灣文化的這個銓釋能力。」
學者分析,政府積極開放台灣主權AI的訓練語料庫,除了在網路華文世界爭取繁體中文的主權,也是基礎建設的建構、語言主權的掌控,以及台灣文化價值的散播。
淡江大學資工系兼任助理教授/台灣數位理協會常務理事張榮貴指出,「你沒做,那更抓不到, 那應該是說,我們把它整理,有計畫的釋出的話,那對於這些做模型的公司,如果知道這些訊息,那可能就會來拿去引用。」
數發部次長侯宜秀認為,「希望我們孩子們用的AI,是像台灣、像我們講話方式的AI,是分享我們價值的AI。」
數發部強調,語料庫透過合法授權,提供給AI模型訓練的工程師運用,這些給AI的教材,幫助AI模型更容易了解台灣,也學會更貼近台灣社會的語言表達能力,也希望公私協力提供資料,豐富語料庫。
許勝婕/編輯