不讓台灣語言缺席AI數位語料 民間團體號召作家打造資料庫
加入公視會員,
按讚收藏你關注的報導
發布時間:
更新時間:
生成式AI席捲全球,但目前主流AI模型多以英文與簡體中文為主要訓練基礎,讓台灣的語言、價值觀在數位語料中嚴重缺席。IMA資訊經理人協會發起「台灣通用語料庫計畫」,希望打造自主、開放、可信的語料體系。
打開ChatGPT提問,民主國家採用的司法、行政、立法「三權分立好不好?」,得到的答案卻全是簡體字。
數位發展部指出,由於當前主流AI模型多以英文與簡體中文為主要訓練基礎,因此常常可以發現,AI答案不只文字,有時跟台灣觀點也有落差。
數位發展部次長林宜敬指出,「我們不能讓這種狀況發生,也就是全世界的AI模型都是由簡體中文語料去訓練,結果訓練出來的都會是跟我們不一樣的價值觀。」
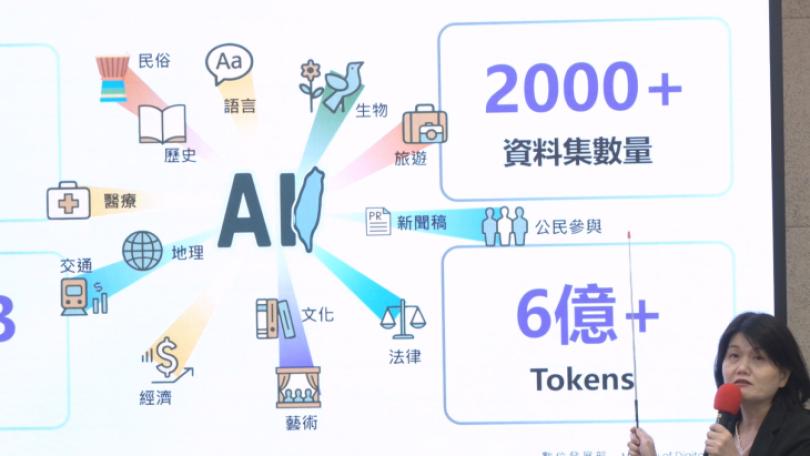
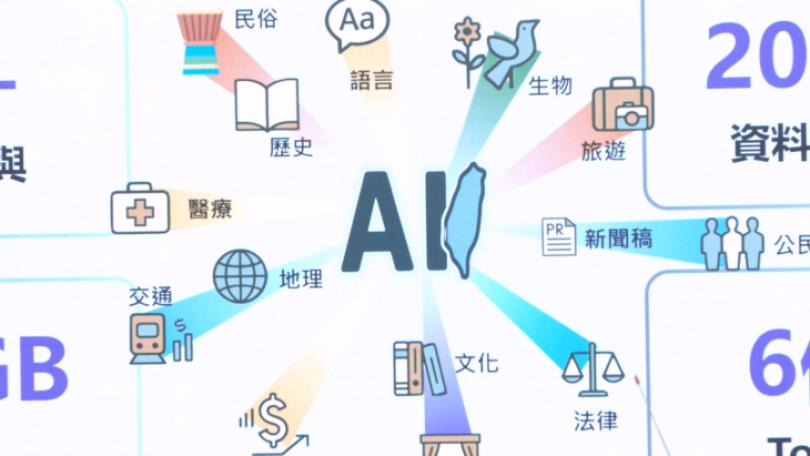
為了避免台灣的華、台、客、原住民族語在數位語料缺席,導致AI難以理解台灣的語言與文化,IMA資訊經理人協會從民間發起「Taiwan Tongues」台灣通用語料庫計畫,在尊重智慧財產權的前提下,號召作家無償釋出文學作品,共同擴大台灣語料庫,以母語書寫的作家向陽已響應授權。
向陽表示,「這不只是台語跟新科技、新世紀的對話,而且也是台灣語言文化進一步邁向國際通行語言的最好機會。」
IMA資訊經理人協會理事長蔡祈岩指出,「這件事不是打高空,而是很重要的基礎建設,把基礎打好了,在這個土壤上,台灣的AI就會有很好的發展。」
不希望主流AI模型導致台灣掉落新的數位落差與文化邊緣化,目前台灣通用語料庫計畫已經有數十位作家授權,累計超過500萬字高品質語料陸續上架提供非商業使用,期待讓AI不再是中國或外國腔。
李彥穎/編輯